











Các kiểu dữ liệu trong MySQL mà bạn nên biết để quản trị dữ liệu
Thịnh Văn Hạnh
10/02/2026
4182 Lượt xem
MySQL là một hệ quản trị dữ liệu cơ bản và phổ biến. Khi sử dụng MySQL, bạn phải làm việc với rất nhiều dữ liệu. Muốn làm việc hiệu quả với MySQL bạn phải nắm vững một số kiểu dữ liệu quan trọng. Bài viết dưới đây, BKNS sẽ cung cấp cho bạn toàn bộ thông tin về các kiểu dữ liệu trong MySQL.
Tóm Tắt Bài Viết
Khái niệm dữ liệu và kiểu dữ liệu

Dữ liệu là một tập hợp các dữ kiện, chẳng hạn như số, từ, hình ảnh, nhằm đo lường, quan sát hoặc chỉ là mô tả về sự vật.
Kiểu dữ liệu tức là KIỂU của DỮ LIỆU
Ví dụ về một mẫu dữ liệu mô tả thông tin cơ bản của một người.
| Họ và Tên | Giới tính | Ngày sinh | Địa chỉ | SĐT |
| Vũ Văn Đại | Nam | 07/08/1999 | Huyện Chương Mỹ, Hà Nội | 0987654321 |
Các kiểu dữ liệu có thể thấy thông qua ví dụ này là:
- VŨ VĂN ĐẠI, có dạng chuỗi ký tự, nên người ta gọi cột Họ và Tên có kiểu dữ liệu là kiểu chuỗi.
- Tương tự với cột Giới tính và Địa chỉ, đây cũng là dữ liệu có dạng chuỗi ký tự cho nên nó là kiểu chuỗi.
- Với cột Ngày sinh, có dạng ngày tháng (07/08/1999) nên được xem là kiểu ngày tháng (thời gian)
- Dữ liệu ở cột SĐT có dạng số nguyên (0987654321), nên người ta gọi cột này có kiểu dữ liệu là kiểu số.
Kiểu dữ liệu số

Đây là một trong những kiểu dữ liệu thịnh hành trong MySQL. Kiểu dữ liệu này được phân ra làm kiểu dữ liệu số nguyên, kiểu dữ liệu số thực, kiểu dữ liệu DECIMAL và NUMERIC.
- Có thể bạn quan tâm: MySQL là gì? Hướng dẫn cài đặt và cấu hình MySQL
Kiểu dữ liệu số nguyên
Các kiểu số nguyên tiêu chuẩn của MySQL là INTEGER (INT) và SMALLINT. Hơn nữa, MySQL còn hỗ trợ các kiểu số nguyên khác như TINYINT, MEDIUMINT, và BIGINT. Mỗi kiểu dữ liệu có không gian lưu trữ khác nhau.
| TINYINT | SMALLINT | MEDIUMINT | INT | BIGINT | |
| Độ dài (số byte) | 1 | 2 | 3 | 4 | 8 |
| Giá trị lưu trữ (có dấu) | -128 -127 | -32768 -32767 | -8388608 – 8388607 | -2147483648 – 2147483647 | -9223372036854775808
– 92233720368 54775807 |
| Giá trị lưu trữ (không dấu) | 0 – 255 | 0 – 65535 | 0 – 16777215 | 0 – 4294967295 | 0 – 184467440737 09551615 |
Kiểu dữ liệu số thực
Kiểu dữ liệu FLOAT và DOUBLE mô tả gần đúng các giá trị số thực.
| FLOAT | DOUBLE | |
| Mô tả | Một số chấm động (floating-point number) không thể không có dấu (unsigned). Bạn có thể định nghĩa độ dài phần nguyên (M) và độ dài phần thập phân (D). Điều này không bắt buộc và mặc định là 10,2. Ở đây 10 là độ dài phần nguyên còn 2 là số số thập phân. | Một số chấm động DOUBLE (Độ chính xác gấp 2) cũng không thể không có dấu (unsigned). Bạn có thể định nghĩa độ dài phần nguyên (M) và độ dài phần thập phân (D). Điều này không bắt buộc và mặc định là 16,4, ở đó 16 là độ dài phần nguyên còn 4 là độ dài phần thập phân. Phần thập phân có thể sử dụng tới 53 vị trí cho một số DOUBLE. REAL là một từ đồng nghĩa với DOUBLE. |
| Độ dài (số byte) | 4 | 8 |
| Giá trị lưu trữ (có dấu) | -3.402823466E+38 – -1.175494351E-38 | -1.7976931348623157E+ 308 – -2.2250738585072014E- 308 |
| Giá trị lưu trữ (không dấu) | 1.175494351E-38 – 3.402823466E+38 | 0 and 2.2250738585072014E- 308 – 1.7976931348623157E+ 308 |
Kiểu dữ liệu DECIMAL và NUMERIC
Trong MySQL kiểu DECIMAL và NUMERIC lưu trữ chính xác các dữ liệu số. MySQL 5.6 lưu trữ giá trị DECIMAL theo định dạng nhị phân.
Trong SQL chuẩn, cú pháp DECIMAL(5,2) nghĩa là độ chính xác (precision) là 5, và 2 là phần thập phân (scale), nghĩa là nó có thể lưu trữ một giá trị có 5 chữ số trong đó có 2 số thập phân. Vì vậy giá trị lưu trữ sẽ là -999.99 tới 999.99. Cú pháp DECIMAL(M) tương đương với DECIMAL(M,0). Tương tự DECIMAL tương đương với DECIMAL(M,0) ở đây M mặc định là 10. Độ dài tối đa các con số cho DECIMAL là 65.
Kiểu dữ liệu Bit
Kiểu dữ liệu BIT được sử dụng để lưu trữ trường giá trị bit. Kiểu BIT(N) có thể lưu trữ N giá trị bit. N có phạm vi từ 1 tới 64. Để chỉ định giá trị các bit, có thể sử dụng b’value’. value là dẫy các số nhị phân 0 hoặc 1. Ví dụ b’10111′ mô tả số 23, và b’100000′ mô tả số 32. Thông thạo chuyển đổi từ hệ nhị phân sang hệ thập phân và ngược lại để dễ dàng hiểu về kiểu dữ liệu này hơn nhé.
Kiểu dữ liệu chuỗi
Các kiểu dữ liệu chuỗi bao gồm:
- CHAR
- VARCHAR
- BINARY
- VARBINARY
- BLOB
- TEXT
- ENUM
- SET
Kiểu dữ liệu CHAR và VARCHAR
Hai kiểu dữ liệu này khá giống nhau. Điểm khác duy nhất của chúng là cách chúng được lưu trữ và truy xuất. Ngoài ra thì chiều dài tối đa và giữ lại hay không khoảng trắng phía trước (trailing spaces) cũng là điểm khác biệt
Kiểu dữ liệu BINARY và VARBINARY
Tương tự như CHAR và VARCHAR nhưng BINARY và VARBINARY có chứa các chuỗi nhị phân chứ không phải là chuỗi non-binary.
Kiểu dữ liệu BLOB và TEXT
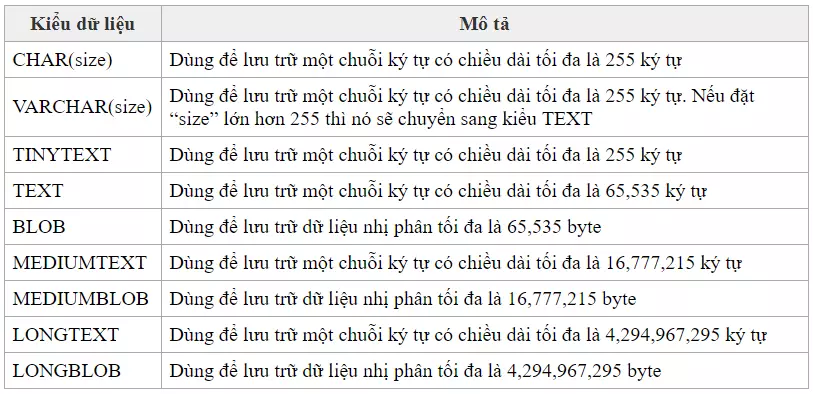
BLOB là một đối tượng nhị phân lớn (Binary Large OBject) có thể chứa một lượng lớn dữ liệu. Có TINYBLOB, BLOB, MEDIUMBLOB, và LONGBLOB. Về cơ bản thì chúng chỉ khác nhau về độ dài kí tự được phép lưu trữ.
Tương tự như BLOB, TEXT cũng có TINYTEXT, MEDIUMTEXT và LONGTEXT.
Kiểu dữ liệu ENUM
Khi định nghĩa một trường kiểu này, tức là, ta đã chỉ ra một danh sách các đối tượng mà trường phải nhận (có thể là Null).Ví dụ, nếu ta muốn một trường nào đó chỉ nhận một trong các giá trị “A” hoặc “B” hoặc “C” thì ta phải định nghĩa kiểu ENUM cho nó như sau: ENUM (‘A’, ‘B’, ‘C’). Và chỉ có các giá trị này (hoặc NULL) có thể xuất hiện trong trường đó.
Kiểu dữ liệu thời gian
Các kiểu dữ liệu ngày tháng và thời gian đại diện bao gồm DATE, TIME, DATETIME, TIMESTAMP, and YEAR. Cùng khám phá cách hiển thị thời gian qua các kiểu dữ liệu trong mySQL như nào nhé
Kiểu dữ liệu DATETIME, DATE, và TIMESTAMP
| DATETIME | DATE | TIMESTAMP | |
| Mô tả | Sử dụng khi bạn cần giá trị lưu trữ cả hai thông tin ngày tháng và thời gian. | Sử dụng khi bạn muốn lưu trữ chỉ thông tin ngày tháng. | Lưu trữ cả hai thông tin ngày tháng và thời gian. Giá trị này sẽ được chuyển đổi từ múi giờ hiện tại sang UTC trong khi lưu trữ, và sẽ chuyển trở lại múi giờ hiện tại khi lấy dữ liệu ra. |
| Định dạng | YYYY-MM-DD HH:MM:SS | YYYY-MM-DD | YYYY-MM-DD HH:MM:SS |
| Phạm vi | ‘1000-01-01 00:00:00’ to ‘9999-12-31 23:59:59’. | ‘1000-01-01’ to ‘9999-12-31’. | ‘1970-01-01 00:00:01’ UTC to ‘2038-01-19 03:14:07’ UTC |
Kiểu dữ liệu TIME(fsp)
hiển thị thời gian theo định dạng ‘'HH:MM:SS' (hoặc định dạng 'HHH:MM:SS' đối với các giá trị giờ lớn). Giá trị của TIME có thể trong khoảng '-838:59:59' tới '838:59:59'. Phần thời gian có thể lớn bởi vì kiểu TIME có thể không chỉ mô tả thời gian của một ngày (Vốn chỉ có tối đa 24 giờ), mà nó có thể là thời gian trôi qua hoặc khoảng thời gian giữa hai sự kiện (Cái mà có thể lớn hơn 24h thậm trí có giá trị âm).
Kiểu dữ liệu YEAR
Kiểu dữ liệu YEAR được sử dụng 1-byte để mô tả giá trị. Với định dạng 4 số, MySQL hiển thị giá trị YEAR theo định dạng YYYY, với phạm vi 1901 tới 2155, hoặc 0000. Với định dạng 2 số, MySQL chỉ hiển thị 2 số cuối; ví dụ 45 (1945 hoặc 2045)
Kiểu dữ liệu hiện đại & đặc biệt trong MySQL: Từ JSON đến Vector cho AI
Trong kỷ nguyên dữ liệu lớn và trí tuệ nhân tạo, MySQL không còn chỉ là một cơ sở dữ liệu quan hệ thuần túy với những bảng biểu cứng nhắc. Để đáp ứng nhu cầu xử lý dữ liệu linh hoạt, MySQL đã tiến hóa mạnh mẽ với các kiểu dữ liệu hiện đại.
Việc hiểu và vận dụng đúng các kiểu dữ liệu đặc biệt này không chỉ giúp tối ưu hiệu suất hệ thống mà còn mở ra khả năng xử lý các bài toán phức tạp như bản đồ số, dữ liệu phi cấu trúc hay thậm chí là tích hợp AI.
1. Kiểu JSON: Cầu nối giữa RDBMS và thế giới phi cấu trúc
Sự ra đời của kiểu dữ liệu JSON (từ phiên bản 5.7) đã xóa nhòa ranh giới giữa MySQL và các cơ sở dữ liệu NoSQL như MongoDB. Thay vì lưu trữ dưới dạng văn bản (Text) thô sơ, MySQL lưu trữ JSON dưới dạng nhị phân, cho phép truy cập nhanh vào các phần tử bên trong mà không cần phân tích cú pháp (parse) lại toàn bộ tài liệu.
Cách MySQL xử lý dữ liệu không cấu trúc
Khi sử dụng kiểu JSON, MySQL cung cấp khả năng kiểm soát dữ liệu cực kỳ linh hoạt. Dữ liệu được tự động kiểm tra định dạng (validation) ngay khi chèn vào, đảm bảo tính toàn vẹn của cấu trúc. Điều này cực kỳ hữu ích cho các thuộc tính sản phẩm biến đổi liên tục hoặc các cấu hình hệ thống phức tạp.
Sức mạnh từ hàm JSON_EXTRACT
Điểm thực sự làm nên khác biệt là khả năng truy vấn sâu. Với hàm JSON_EXTRACT hoặc toán tử rút gọn ->>, bạn có thể truy xuất chính xác một giá trị trong một tài liệu JSON khổng lồ.
- Hiệu năng: Bạn có thể tạo Generated Columns (Cột ảo) dựa trên một trường trong JSON và đánh Index trên đó. Điều này giúp tốc độ truy vấn dữ liệu bên trong JSON nhanh tương đương với các cột thông thường.
2. Kiểu ENUM & SET: Tối ưu hóa lưu trữ và tốc độ
Nếu bạn có một danh sách các giá trị cố định và ít thay đổi (ví dụ: Giới tính, Trạng thái đơn hàng, Ngày trong tuần), ENUM và SET là những lựa chọn hàng đầu để tối ưu hóa tài nguyên.
Ưu điểm vượt trội về tốc độ
- Tiết kiệm không gian: Thay vì lưu trữ các chuỗi văn bản dài, MySQL lưu trữ ENUM dưới dạng các số nguyên (1, 2, 3…) tương ứng với các giá trị bạn định nghĩa. Điều này làm giảm đáng kể kích thước bảng và tăng tốc độ so sánh dữ liệu.
- Kiểm soát dữ liệu: Nó đóng vai trò như một bộ lọc ngay tại tầng Database, ngăn chặn việc chèn các giá trị lạ không nằm trong danh sách cho phép.
Nhược điểm và thách thức khi mở rộng
Mặc dù hiệu quả, ENUM là một “con dao hai lưỡi” khi hệ thống cần mở rộng:
- Khó thay đổi: Mỗi khi bạn muốn thêm một giá trị mới vào danh sách ENUM, MySQL thường phải thực hiện thao tác ALTER TABLE, điều này có thể gây khóa bảng (lock table) đối với các bảng có hàng triệu bản ghi.
- Tính linh hoạt thấp: ENUM không phù hợp nếu danh sách giá trị của bạn thường xuyên thay đổi hoặc được quản lý bởi người dùng cuối.
3. Kiểu Spatial (Không gian): Nền tảng cho ứng dụng bản đồ
Trong thế giới của Grab, Google Maps hay các ứng dụng định vị, kiểu dữ liệu Spatial là “xương sống” để xử lý các truy vấn liên quan đến vị trí địa lý.
- POINT: Lưu trữ một tọa độ cụ thể (Kinh độ, Vĩ độ). Đây là kiểu dữ liệu cơ bản nhất để đánh dấu một vị trí trên bản đồ.
- POLYGON: Cho phép định nghĩa một vùng không gian (ví dụ: ranh giới của một quận, một khu dân cư hoặc một vùng giao hàng).
MySQL hỗ trợ các hàm tính toán khoảng cách như ST_Distance hoặc kiểm tra xem một điểm có nằm trong một vùng hay không với ST_Contains. Nhờ có Spatial Indexes (R-tree), việc tìm kiếm “các cửa hàng trong bán kính 5km” trở nên nhanh chóng ngay cả với hàng triệu tọa độ.
4. Kiểu VECTOR: Bước tiến đột phá cho kỷ nguyên AI
Một trong những cập nhật thú vị nhất trong các phiên bản MySQL gần đây (8.0.30+ và MySQL 9.x) chính là sự xuất hiện của kiểu dữ liệu VECTOR. Đây là lời giải cho bài toán tích hợp AI trực tiếp vào cơ sở dữ liệu.
Phục vụ cho AI và Tìm kiếm ngữ nghĩa (Semantic Search)
Thông thường, các mô hình học máy (như OpenAI, BERT) sẽ chuyển đổi văn bản, hình ảnh hoặc âm thanh thành các dãy số dài gọi là Embeddings (Vector).
- Tìm kiếm theo ý nghĩa: Thay vì tìm kiếm theo từ khóa chính xác (Keyword search), kiểu VECTOR cho phép bạn tìm kiếm theo độ tương đồng. Ví dụ: Tìm các bài viết có nội dung “tương tự” với bài viết hiện tại bằng cách tính toán khoảng cách giữa các Vector.
- Ứng dụng: Xây dựng hệ thống gợi ý sản phẩm, nhận diện khuôn mặt, hoặc các hệ thống Chatbot RAG (Retrieval-Augmented Generation) hiện đại ngay trên MySQL mà không cần cài đặt thêm các Vector Database chuyên dụng như Pinecone hay Milvus.
5 Quy tắc “vàng” khi chọn kiểu dữ liệu
Việc chọn sai kiểu dữ liệu ngay từ đầu giống như việc xây móng nhà bằng cát; hệ thống có thể vẫn chạy được lúc đầu, nhưng sẽ đổ vỡ khi quy mô dữ liệu lớn dần. Để trở thành một kiến trúc sư dữ liệu thực thụ, bạn cần nằm lòng 5 quy tắc “vàng” dưới đây để tối ưu hóa hiệu suất và độ tin cậy cho MySQL.
Quy tắc 1: Chọn kiểu nhỏ nhất có thể (Smallest fits)
Đừng luôn chọn BIGINT cho một cột chỉ chứa số thứ tự nhỏ, hay DATETIME khi bạn chỉ cần lưu năm.
- Lý do: Dữ liệu càng nhỏ, CPU xử lý càng nhanh, bộ nhớ đệm (RAM) chứa được nhiều bản ghi hơn và I/O đĩa cứng giảm đi đáng kể.
- Ví dụ: Nếu một cột chỉ lưu trữ trạng thái từ 0 đến 5, hãy dùng TINYINT (1 byte) thay vì INT (4 bytes). Tiết kiệm 3 bytes có vẻ ít, nhưng với 100 triệu dòng, bạn đã tiết kiệm được gần 300MB dung lượng lưu trữ và băng thông bộ nhớ.
Quy tắc 2: Ưu tiên số hơn chuỗi (Numbers over Strings)
Trong các thao tác tìm kiếm (WHERE) và sắp xếp (ORDER BY), máy tính xử lý các con số nhanh hơn rất nhiều so với các chuỗi ký tự.
- Tại sao? Việc so sánh hai số nguyên chỉ mất một chu kỳ CPU đơn giản, trong khi so sánh chuỗi yêu cầu máy tính phải quét qua từng ký tự, xem xét quy tắc sắp xếp (Collation) và mã hóa (Encoding).
- Áp dụng: Thay vì lưu địa chỉ IP dưới dạng VARCHAR(15), hãy dùng hàm INET_ATON() để chuyển sang kiểu số nguyên. Tương tự, hãy dùng mã ID thay vì dùng tên định danh trực tiếp trong các cột thường xuyên dùng để lọc dữ liệu.
Quy tắc 3: Luôn sử dụng DECIMAL cho tiền tệ
Đây là quy tắc sống còn đối với các ứng dụng tài chính và thương mại điện tử.
- Vấn đề với FLOAT/DOUBLE: Các kiểu dữ liệu số thực này sử dụng định dạng nhị phân xấp xỉ, dẫn đến các lỗi làm tròn kinh điển (ví dụ: 0.1 + 0.2 có thể ra 0.30000000000000004). Trong giao dịch tiền tệ, sai lệch dù chỉ 0.0001 cũng là thảm họa.
- Giải pháp: Kiểu DECIMAL(precision, scale) lưu trữ số dưới dạng chuỗi định dạng chính xác tuyệt đối.
- Ví dụ: DECIMAL(19, 4) cho phép lưu trữ số tiền cực lớn với độ chính xác đến 4 chữ số thập phân, đảm bảo sự minh bạch trong sổ sách kế toán.
Quy tắc 4: Tách biệt TEXT/BLOB sang bảng phụ
Như đã đề cập ở phần trước, các kiểu dữ liệu lớn như TEXT và BLOB thường được MySQL lưu trữ bên ngoài bảng chính.
- Chiến lược tối ưu: Nếu bạn có một bảng Users chứa thông tin đăng nhập và một cột Bio (tiểu sử dài), hãy tách cột Bio sang bảng User_Profiles.
- Lợi ích: Khi bạn thực hiện truy vấn danh sách người dùng để hiển thị tên và email, MySQL không phải tải các khối dữ liệu “Bio” cồng kềnh vào bộ nhớ, giúp tốc độ phản hồi cực nhanh.
Quy tắc 5: Đồng nhất kiểu dữ liệu giữa Khóa chính và Khóa ngoại
Đây là lỗi phổ biến khiến các liên kết bảng (JOIN) trở nên chậm chạp hoặc thậm chí bị lỗi.
- Quy tắc: Cột Khóa ngoại (Foreign Key) phải có kiểu dữ liệu tuyệt đối chính xác với Khóa chính (Primary Key) mà nó tham chiếu đến.
- Chi tiết: Nếu Khóa chính là INT UNSIGNED, thì Khóa ngoại cũng phải là INT UNSIGNED. Nếu một bên là INT (có dấu) và một bên là UNSIGNED (không dấu), MySQL sẽ phải thực hiện chuyển đổi kiểu dữ liệu (Implicit Conversion) cho mỗi dòng dữ liệu khi JOIN, làm mất tác dụng của Index và làm sập hiệu suất hệ thống.
Các lỗi thường gặp và cách khắc phục
Dưới đây là phân tích chi tiết về 3 sai lầm phổ biến nhất và giải pháp khắc phục triệt để:
Lưu ngày tháng dưới dạng chuỗi (VARCHAR)
Đây là lỗi phổ biến nhất của các lập trình viên mới, khi muốn lưu trữ ngày tháng theo định dạng mong muốn (ví dụ: 31/12/2023) một cách nhanh chóng.
Hậu quả:
- Không thể tính toán: Bạn không thể thực hiện các phép cộng/trừ ngày tháng trực tiếp hoặc sử dụng các hàm hữu ích như DATEDIFF(), DATE_ADD().
- Sắp xếp sai lệch: Khi sắp xếp (Order By), MySQL sẽ sắp xếp theo thứ tự bảng chữ cái. Kết quả là ngày 01/01/2024 sẽ đứng trước 31/12/2023 chỉ vì số “0” nhỏ hơn số “3”.
- Hiệu suất kém: Việc so sánh chuỗi luôn chậm hơn so với so sánh giá trị số/ngày tháng nhị phân.
Cách khắc phục:
- Sử dụng đúng kiểu dữ liệu: Luôn dùng DATE, DATETIME hoặc TIMESTAMP.
- Tách biệt lưu trữ và hiển thị: Hãy lưu trữ dưới định dạng chuẩn của MySQL (YYYY-MM-DD). Khi cần hiển thị ra ngoài giao diện, hãy sử dụng hàm DATE_FORMAT(column,’%d/%m/%Y’).
2. Lạm dụng LONGTEXT gây chậm truy vấn
Kiểu dữ liệu LONGTEXT có thể lưu trữ tới 4GB dữ liệu, điều này khiến nhiều người lầm tưởng rằng “cứ dùng cho chắc” để tránh tràn dữ liệu.
Hậu quả:
- Tốn bộ nhớ đệm (Buffer Pool): Khi bạn thực hiện lệnh SELECT *, MySQL buộc phải đọc các khối dữ liệu khổng lồ từ đĩa cứng vào bộ nhớ RAM, làm cạn kiệt tài nguyên hệ thống.
- Lạm dụng Disk Temporary Tables: Các truy vấn chứa cột LONGTEXT thường không thể xử lý hoàn toàn trên RAM mà phải tạo các bảng tạm thời trên ổ đĩa, khiến tốc độ truy vấn giảm đi hàng chục lần.
Cách khắc phục:
- Đúng người đúng việc: Chỉ dùng TEXT hoặc LONGTEXT cho nội dung bài viết, mô tả sản phẩm dài. Đối với tiêu đề, email, tên người dùng, hãy trung thành với VARCHAR với độ dài hợp lý (ví dụ: VARCHAR(255)).
- Kỹ thuật truy vấn: Tránh tuyệt đối SELECT*. Chỉ gọi tên cột LONGTEXT khi thực sự cần hiển thị nội dung đó.
3. Quên cấu hình Character Set (utf8mb4) dẫn đến lỗi font
Nhiều lập trình viên vẫn giữ thói quen sử dụng utf8. Tuy nhiên, trong MySQL, utf8 thực chất chỉ hỗ trợ tối đa 3 byte cho mỗi ký tự, không đủ để hiển thị trọn vẹn các ký tự phức tạp và Emoji.
Hậu quả:
- Lỗi hiển thị: Tiếng Việt có dấu bị biến thành các ký tự lạ như “ hoặc ?.
- Mất dữ liệu: Các biểu tượng cảm xúc (Emoji) từ người dùng sẽ không thể lưu trữ được, gây lỗi truy vấn khi chèn dữ liệu.
Cách khắc phục:
- Sử dụng utf8mb4: Đây là bộ mã hóa chuẩn nhất hiện nay, hỗ trợ đầy đủ tiếng Việt và mọi loại Emoji.
- Cấu hình đồng bộ: Đảm bảo thiết lập utf8mb4 ở cả 3 cấp độ:
- Database: CREATE DATABASE mydb CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
- Table: Đảm bảo các bảng cũng kế thừa bộ mã này.
- Connection: Chuỗi kết nối từ ứng dụng (PHP, Node.js, Python…) phải khai báo charset là utf8mb4.
Kết luận

Trên đây là bài viết BKNS cung cấp về các kiểu dữ liệu trong mySQL. Sau bài viết này chắc hẳn bạn đã biết phân loại và hiểu rõ hơn những kiến thức về các kiểu dữ liệu trong mySQL. HY vọng bạn thấy bài viết hữu ích. Nếu còn bất cứ thắc mắc gì thì hãy cứ comment bên dưới để được hỗ trợ và giải đáp tận tình nhé!
Đọc thêm:
Các Kiểu Dữ Liệu Trong SQL Server: Bạn Có Biết?
Hướng dẫn xuất cơ sở dữ liệu SQL Server thành file .sql để import trên phiên bản SQL Server thấp hơn